Designing closer to code
I've used Figma for years, and it will remain an essential tool in my stack, just as much as the humble pen and paper. However, the reach of its utility has certainly compressed with the introduction of AI.
My gripe with the past process was that design implementation often go through minor tweaks before deployment, maybe some copy changes or edge case handling - they warrant design input but not a full rework cycle. And here's the issue, these adjustments rarely sync back to Figma, so over time, you get a drift with production. Designers want to maintain this, but usually have their hands full on the next feature.
Designing with HTML
AI fixes the sync back issue by allowing me to design with the code i.e. the source of truth. Exploration should still take place outside in Figma or paper, but once you have a flow in mind, these days I will present the flow to Claude, ask him to pull existing design components, and draft the design in a single HTML, refine, and use this as a basis for the build. This allows me to always design from the source of truth, the codebase.
I actually picked up this trick using Claude Design, I noticed all the output were HTML and found it pretty useful. However, because of the annoying weekly limits, I ended up adapting this workflow to Claude Code, and I think I'll stick to this setup, I prefer working close to the code.
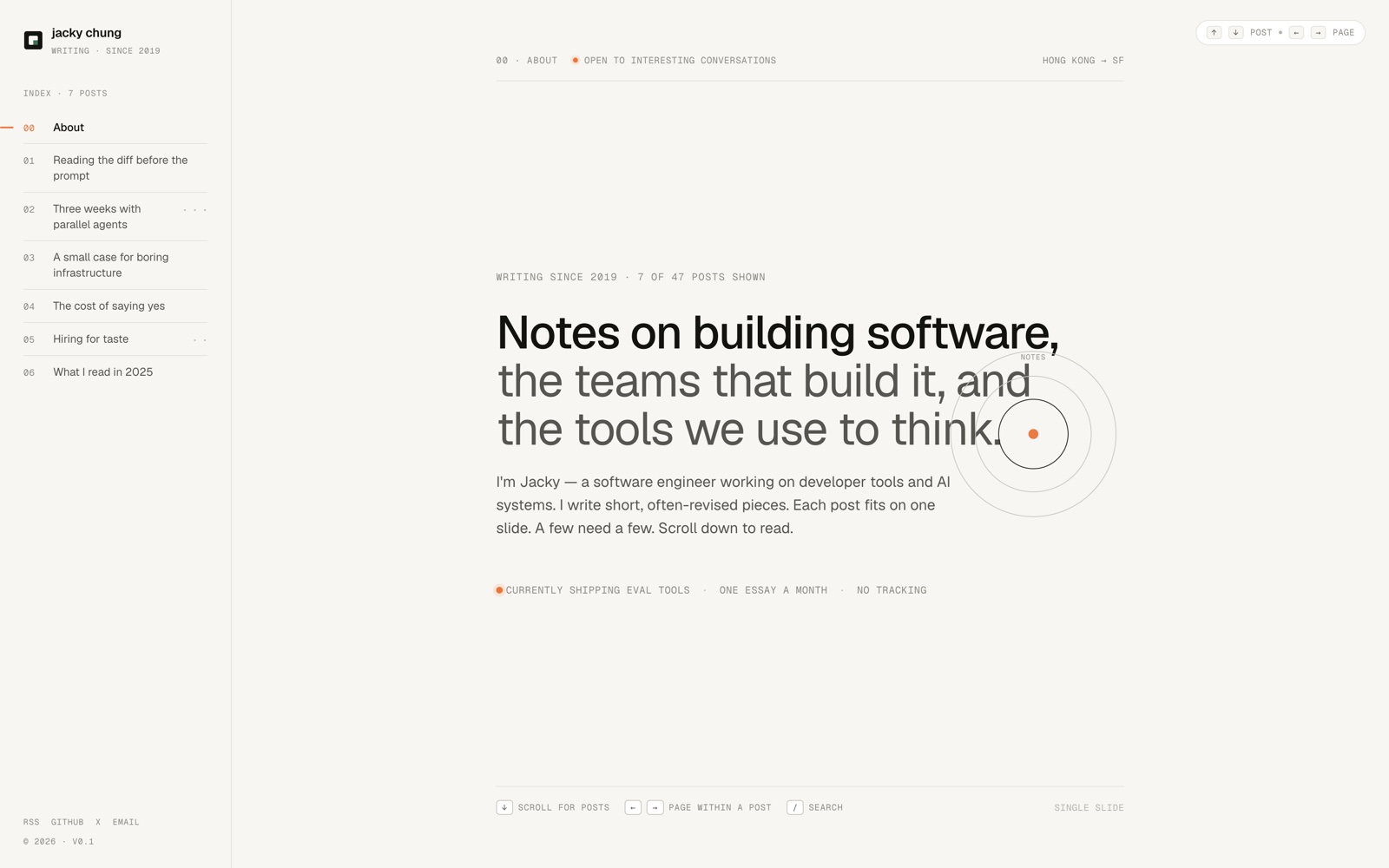
Example 1: HTML Design System
Prompt guide: provide Claude with some reference screenshots and ask it to build a draft design system with it. To refine, ask it to add an html artifact for adjusting colours, type etc.
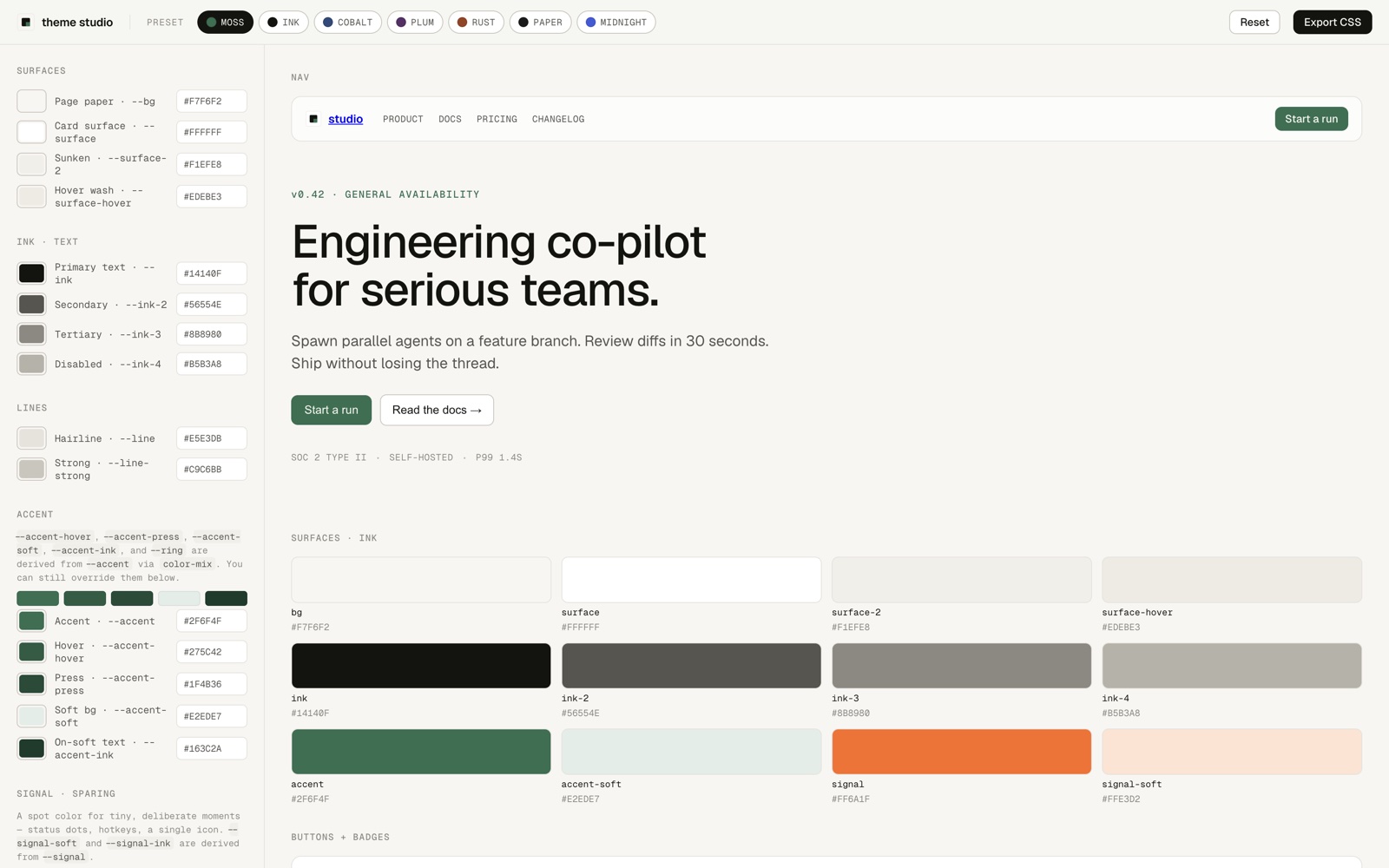
Example 2: HTML Site Mockup
Prompt guide: ask Claude to reference the design system and draft the blog page in a single html file. I specifically asked for an index sidebar and posts loaded on the right.